Brian R.Y. Huang

I’m a machine learning engineer and researcher interested in making frontier AI systems more robust and reliable and in helping disseminate their benefits in an equitable and empowering way.
At MIT, I was fortunate to conduct research on adversarial robustness of deep learning models, advised by Hadi Salman and Aleksander Mądry. I’ve previously worked in finance, robotics, and AI safety research. I currently work on RL and post-training for code at Google DeepMind.
selected works
- Endless Jailbreaks with Bijection LearningICLR, 2025We devise a "bijection attack," an encoding scheme taught to a language model in-context which bypasses model alignment and comprises a highly effective jailbreak. We differentially modulate the complexity of our bijection scheme across different models and derive a quadratic scaling law, finding that, curiously, our bijection attack is stronger on higher-capability models.
-
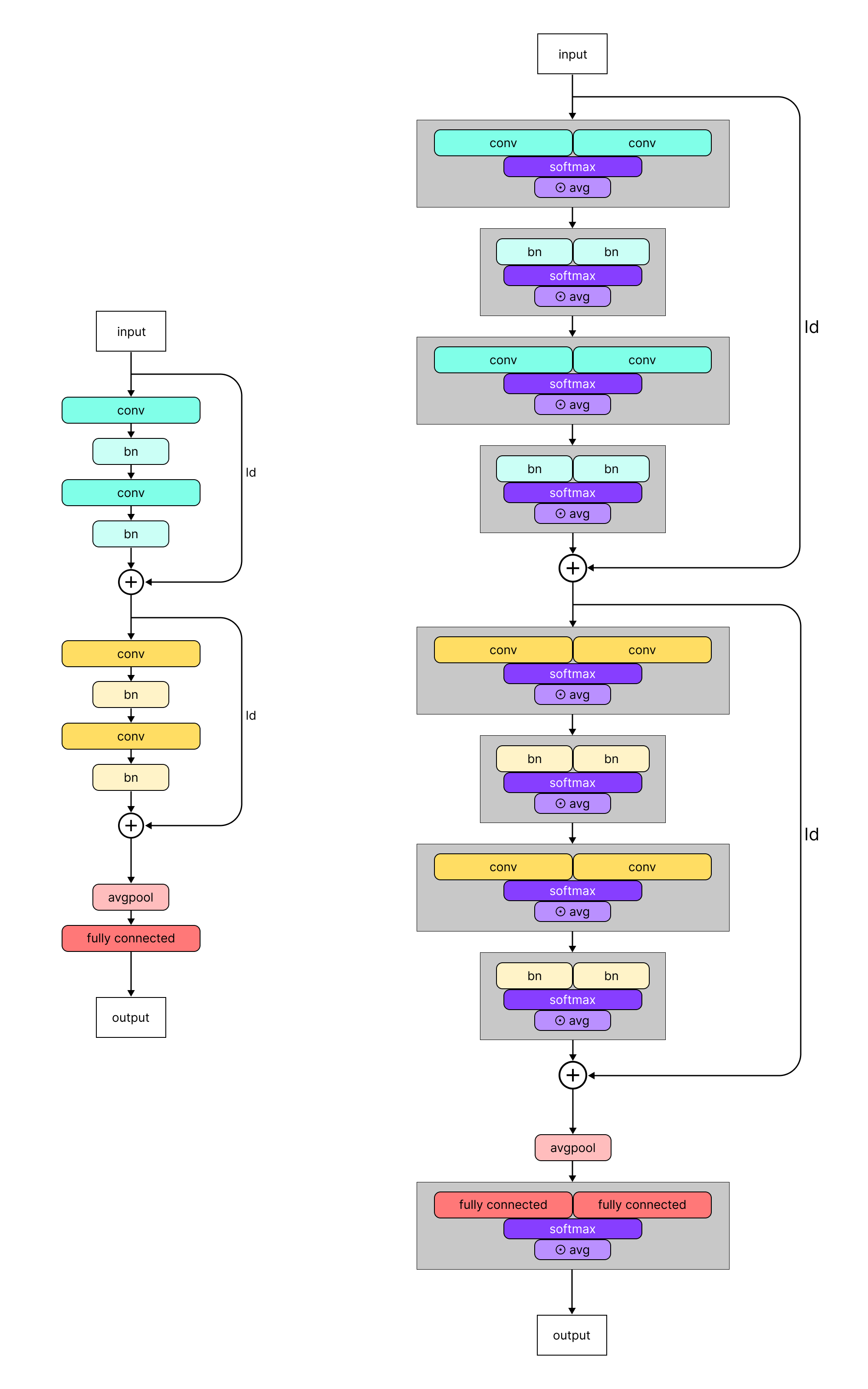 Adversarial Learned Soups: Neural Network Averaging for Joint Clean and Robust PerformanceMaster’s Thesis, 2023Supervised by Hadi Salman and Aleksander Mądry.
Adversarial Learned Soups: Neural Network Averaging for Joint Clean and Robust PerformanceMaster’s Thesis, 2023Supervised by Hadi Salman and Aleksander Mądry.
We introduce weight-space interpolation methods to the adversarial robustness regime, devising a wrapper architecture to optimize the interpolation coefficients of a "model soup" via adversarial training. Varying the intensity of adversarial training (perturbation distance, TRADES weightings, etc.) leads to a smooth tradeoff between the resulting clean and robust accuracy of the interpolated model. - Does It Know?: Probing and Benchmarking Uncertainty in Language Model Latent BeliefsATTRIB Workshop @ NeurIPS, 2023We extend the recent work of Contrast-Consistent Search by Burns et al., 2023, to detect uncertainty in the factual beliefs of language models. We create a toy dataset of timestamped news factoids as a true/false/uncertain classification benchmark for LLMs with a known training cutoff date.
- On Sufficient Conditions for Trapped Surfaces in Spherically Symmetric Spacetimespresented at Siemens Competition, 2017Some differential geometry / general relativity research on black hole formation that I was fortunate to conduct during high school!


