research & projects
publications
2025
- Endless Jailbreaks with Bijection LearningICLR, 2025We devise a "bijection attack," an encoding scheme taught to a language model in-context which bypasses model alignment and comprises a highly effective jailbreak. We differentially modulate the complexity of our bijection scheme across different models and derive a quadratic scaling law, finding that, curiously, our bijection attack is stronger on higher-capability models.

2024
- Plentiful Jailbreaks with String CompositionsSoLaR Workshop @ NeurIPS, 2024We ensemble a large set of string-level obfuscation-based attack mechanisms across the language model redteaming literature. We construct arbitrary compositions of these string-level transformations and devise a simple adaptive attack that is highly effective on frontier models. Small and cute idea that was the precursor for bijection learning.
2023
- Does It Know?: Probing and Benchmarking Uncertainty in Language Model Latent BeliefsATTRIB Workshop @ NeurIPS, 2023We extend the recent work of Contrast-Consistent Search by Burns et al., 2023, to detect uncertainty in the factual beliefs of language models. We create a toy dataset of timestamped news factoids as a true/false/uncertain classification benchmark for LLMs with a known training cutoff date.

preprints
2023
-
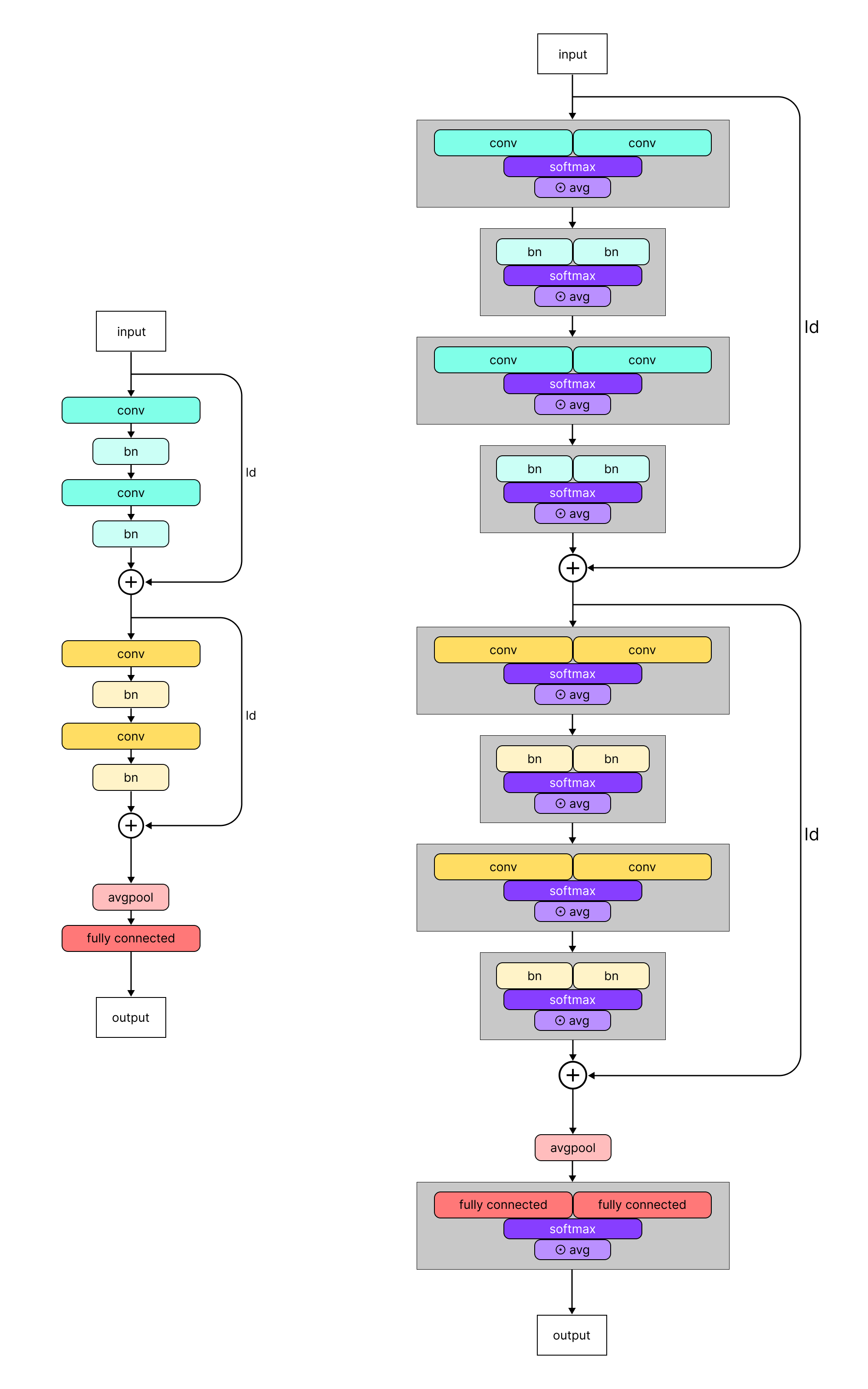 Adversarial Learned Soups: Neural Network Averaging for Joint Clean and Robust PerformanceMaster’s Thesis, 2023Supervised by Hadi Salman and Aleksander Mądry.
Adversarial Learned Soups: Neural Network Averaging for Joint Clean and Robust PerformanceMaster’s Thesis, 2023Supervised by Hadi Salman and Aleksander Mądry.
We introduce weight-space interpolation methods to the adversarial robustness regime, devising a wrapper architecture to optimize the interpolation coefficients of a "model soup" via adversarial training. Varying the intensity of adversarial training (perturbation distance, TRADES weightings, etc.) leads to a smooth tradeoff between the resulting clean and robust accuracy of the interpolated model.

2017
- On Sufficient Conditions for Trapped Surfaces in Spherically Symmetric Spacetimespresented at Siemens Competition, 2017Some differential geometry / general relativity research on black hole formation that I was fortunate to conduct during high school!
miscellaneous
A mix of class projects and internship deliverables during my time at MIT. Not too formal or novel, just exploratory!
2023
- Synthetic Instruction Tuning for Retrieval-Augmented Code Generation2023Final project for 6.S986 Large Language Models and Beyond.
We perform instruction bootstrapping with STaR rationalization (a la Zelikman et al.) to generate diverse synthetic ICL exemplars for code generation in LLMs. For small models, irrelevant or overly lengthy code documentation in the ICL setting hurts codegen performance–RAG is tricky! - Measuring Monosemanticity via Causal Scrubbing2023Final deliverable for Redwood Research REMIX (Winter 2023).
We validate a possible measure for the "degree of monosemanticity" of LLM neurons: use causal mediation techniques to ablate a neuron with a perfectly monosemantic neuron, and measure KL divergence between the resulting logits.
2022
- Markov Chain Monte Carlo for Cipher Breaking2022Final project for 6.437 Inference and Information. We implement the Metropolis-Hastings method for text decoding and experiment with algorithmic optimizations to improve decoding performance and speed.